Data Pipelines
Data Pipelines
Concern regarding building a data processing system
- multiple layered system
- volume of data
- result are not needed to be sent back to client immediately
- event processing pipeline
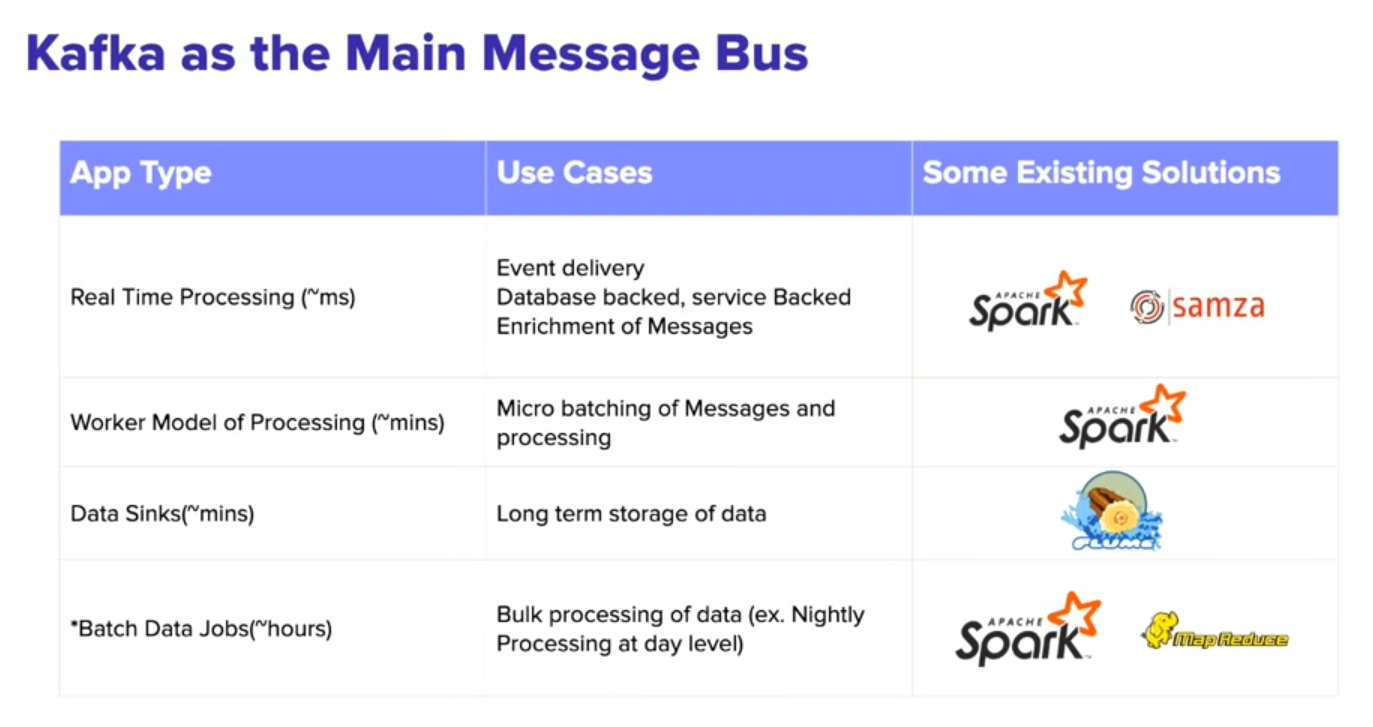
Main Message Bus (Kafka)
- Scaling
- Message semantics
- Repeated pattern of Reading and Writing to the bus makes a pipeline of event processing.
Prerequisite question regarding Data Intensive System
- Is the
data completeor meaning of it? - Is it
consistentwith other data sources, in case of data lake or olap? - If it is
reprocessed, is that data reflective of that, are theSLA's(Service-level agreement) all met? - If some downstream service was down for sometime, did that
impactthe final data?
Concern with pipelines
- How
stableare the underlying systems which generate the data? - How
reliableis the final data even when working with components which go down?
1. Downtime of service
- Services could/should/do go down
- What should a consumer of a service do under such a situation?
- What if, it is a component of a data pipeline
Some solutions
- Fail
fast - Implement a
Dead Letter Queue - The
servicetakes responsibility of ensuring the message is processed
2. Slow consumers
- silent problem in data pipelines when consumer receives more than it can handle
- hard to keep track until data loss happens
- leads to cascading failures of all systems when there is a change in contract or schema.
Some solutions
- Measuring and scaling consumer
- Contract and schema evolution
3. Ensuring zero data loss
- How to make it reliable?
- How do you build a system which continuously processes data with only a few hours of buffer for messages?
4. Global view of the schema
- setting the blueprint/data model of data
- like type, default value, placement etc
- need something to agreed upon by all the producer and consumer
Contract
- A good contract should look like model classes in code-base
- With interactions between different model classes are driven more by the responsibility
Contract Relationship
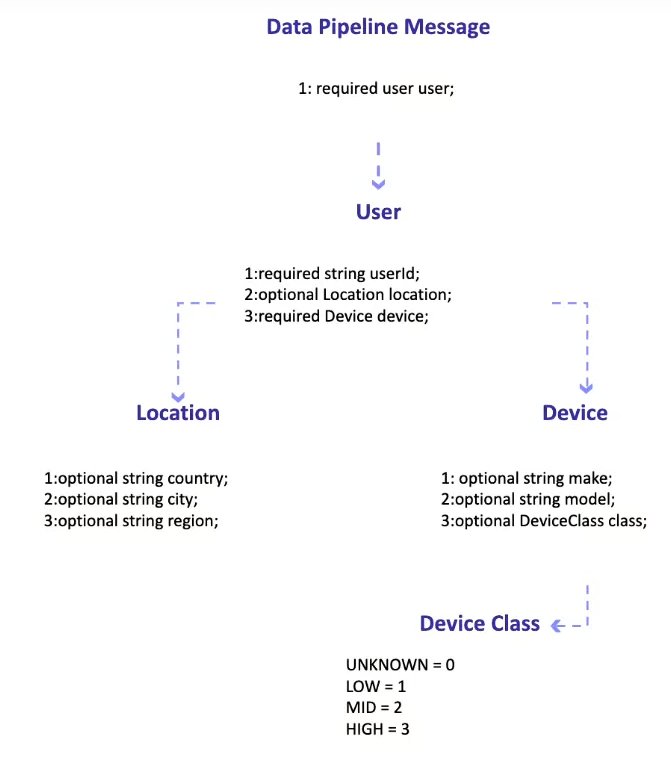
Message Format

Thrift
Thrift is an interface definition language and binary communication protocol used for defining and creating services for numerous languages. It forms a remote procedure call framework.
Advantages of Thrift
- String typing of fields
- Easy renaming of fields and types
- Bindings for all major languages
- Very fast SerDe for messages
Thrift Contract

Compatibility
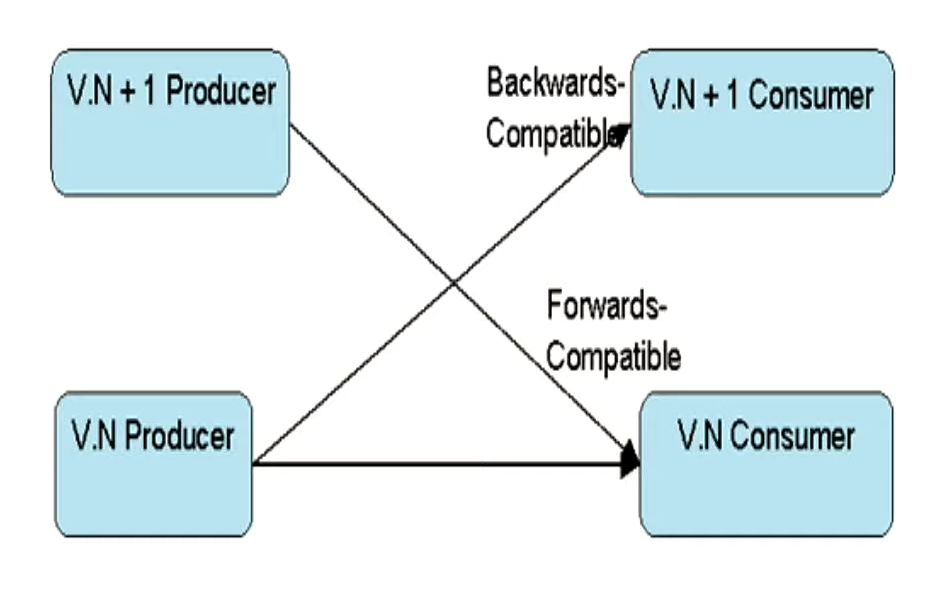
Forward Compatibility and Backward Compatibility
- Producers and Consumers work on different versions of the contract but are able to work well.
Forward Compatibility- Ensure data written today is able to be read and processed in future.
Backward Compatibility- Ensure past data read today is able to be read and processed.
Full Compatibility
Consumers with version
Xof schema are able to read data generated byX, X-1 but not necessarily X-2.Data generated by producers with version
Xof schema is able to be processed by consumers runningX, X-1 versionof schema, not necessarilyX-2.While evolving schema in a compatible way, needs to consider transitivity.
All the data written in the past may not be Fully Compatible in future.
Full Transitive Compatibility via Thrift
- Ensure that the
required fields are never changed/removed - New fields added are only
optional - The index tags are
never changedfor a field - Do not remove optional fields, rename them to
deprecated
References
This post is licensed under CC BY 4.0 by the author.